故障
线上pda服务器出现卡慢,由于pda服务器主要是只是做了网关路由的服务,于是我们猜测是某个下游服务出现了问题,通过elk查看慢请求发现基本是仓储服务的请求很慢。于是我们判断是仓储服务出现了问题。
排查
与此同时,仓储的某台服务器服务心跳消息群里已经告警,我们进入服务器的grafana监控发现,这台服务器cpu已经快100%了,服务器处于假死状态,很久就出现了oom
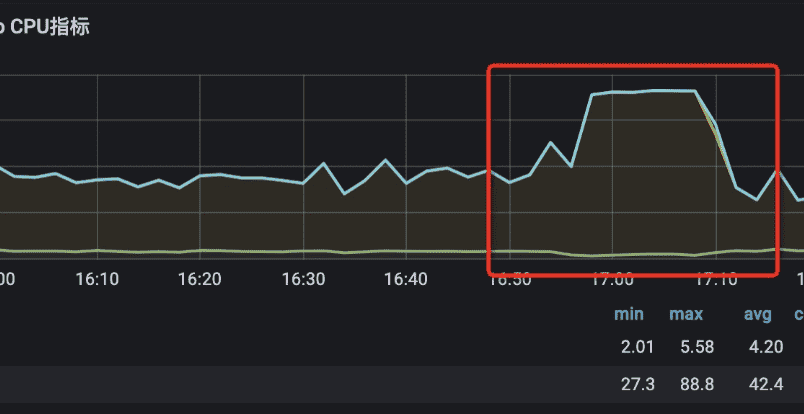
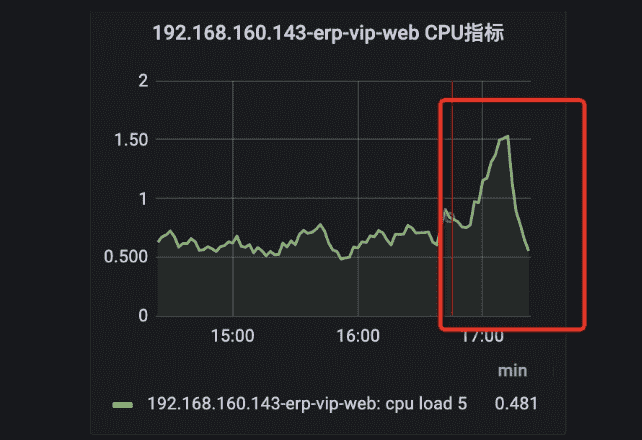
于是我们第一步是把服务器nginx和dubbo下线,
然后,我们这边jvm配置了参数,oom后会自动把堆内存dump下来,
dump完之后我们对服务器进行了重启。同时我们发现这台服务器已经很久没有发布过了,配置又比较低只有4g,最近又拉了500家公司进来,考虑到可能是用户太多服务器扛不住导致的,于是又临时加了一个点分摊压力
dump文件下完后,我们通过eclips的mat工具进行分析,分析后发现整个堆内存的对象总共就只有一个g,那么问题来了,问什么会oom
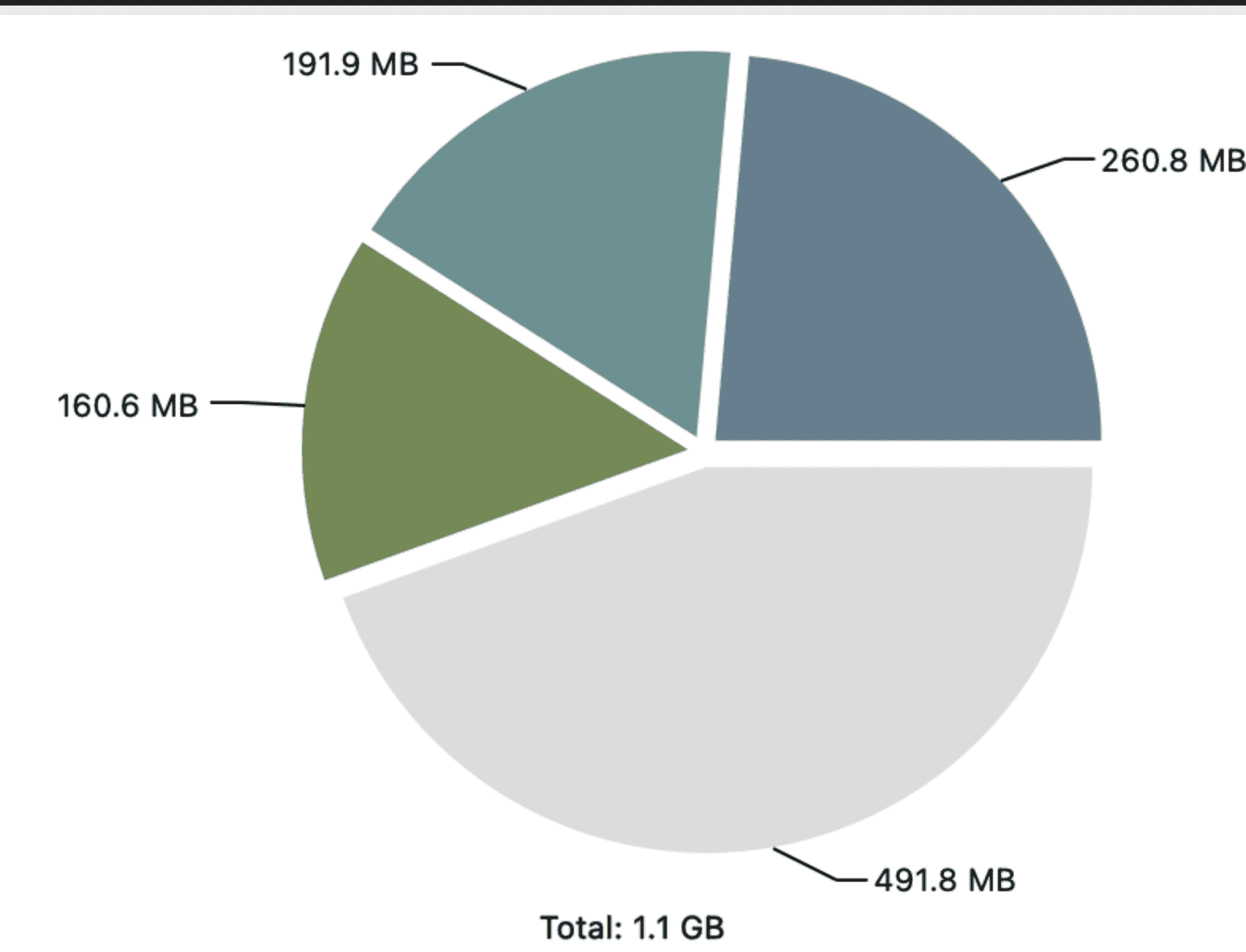
我们查看了oom的报错是overhead limit exceeded,即gc超过一定次数,没有回收出足够的垃圾导致的。于是我们查看了当时的grafana监控,当时fullgc了8次,总共47s,导致服务stoptheworld处于不可用状态,然后仍然没有回收出足够的垃圾,所以最后oom了
我们服务器的jvm配置是-xms 128m -xmx4096m,当时我们查看机器的可用内存已经只有1g了(当然这里也有问题),于是判断是xms设置的太小了,xms是jvm初始堆内存,刚开始只有128m的大小,后来随着对象越来越多,jvm会进行扩容,但是扩容到1g大小的时候,服务器资源就不够了,于是开始fullgc清理垃圾,经过几次fullgc也没有回收足够的空间,所以导致了oom
解决方案
xms设置成跟xmx一致,也能够避免频繁伸缩导致的卡顿