每个线程都有:
- 程序计数器:记录了上下文切换的位置
- 虚拟机栈:由栈帧组成,入栈出栈
- 本地方法栈:Native方法
每个线程共享:
- 堆:对象
- 方法区(jdk8后改名元空间):类信息、常量、静态变量
new 一个对象经历了哪些步骤?
- 类加载检查:使用双亲委派模式,从子类往父类询问是否已经加载到内存?如果都没有加载过。那么再从父类到子类依次尝试加载,把类加载到内存 — 避免类重复加载
- 分配内存:从堆中划一片区域。根据堆内存是否碎片化,划分成两种方法 a. 指针碰撞:堆没有碎片,已分配和未分配有明显的界限。直接移动界限分配内存 b. 空闲列表:堆碎片化,会维护一个列表记录未分配的位置,分配时查找列表找到一个足够大的内存 并发冲突问题:创建对象必须要保证线程安全。jvm为每个线程都预分配了一块内存,当预分配的内存用完时,再使用不断CAS+重试
- 对象初始化
- 引用计数法:每有引用的地方就+1,0为死亡
- 可达性分析:判断对象是否可达gc roots,如果不可达则为死亡
引用计数法无法解决循环引用的问题,所以现在都采用可达性分析法
- 方法运行时,方法中的局部变量的引用对象;
- 类的静态变量、常量的引用对象;
- Native方法中的变量的引用对象。
1. 标记-复制算法
复制算法作为新生代的算法有一段历史演变,一开始是分为两个一样的a、b空间。当a空间满了,就标记活着的对象复制到b空间,然后把a空间清空。但是这样的话,ab空间有一个一直是空的,浪费50%的空间。后来统计发现,新生代每次gc后存活的对象很少,根本不需要50%。
后来就诞生了现在的算法。既把新生代分为eden、s0、s1,默认比例为8:1:1。对象优先在eden中分配,当eden满时触发gc,把其他两个区存活的对象复制到s0或s1(空着的),然后清空其他两个区,年龄+1。
优点:
- 存活对象少时,复制效率高。
- 没有内存碎片
缺点:
- 存活对象多时,复制效率低。
- 需要有一块空间一直空着,浪费内存空间
2. 标记-清除算法
先标记被回收的区域,然后删除
优点:
- 回收对象少的话,效率高
- 不需要额外的空间
缺点:
- 会产生碎片
3. 标记-整理算法
先标记被回收的区域,然后所有存活的对象往一侧移动,清除边界外的
优点:
- 对比标记-清除,没有碎片
- 不需要额外的空间
缺点:
- 比标记-清除耗费时间久
4. 分代算法
新⽣代中,对象存活几率比例低,并且gc频率高,所以适合复制算法。
⽽⽼年代的对象存活⼏率是⽐较⾼的,不适合复制算法,所以我们必须选择“标记-清除”(CMS)或“标记-整理”算法进⾏垃圾收集
在Java堆划分出不同的区域之后,垃圾收集器才可以每次只回收其中某一个或者某些部分的区域。因而才有了“Minor GC”、“Major GC”、“Full GC”这样的回收类型的划分
- 新生代收集(Minor GC/Young GC):指目标只是新生代的垃圾收集
- 老年代收集(Major GC/Old GC):指目标只是老年代的垃圾收集。目前只有CMS收集器会有单独收集老年代的行为。
- 整堆收集(Full GC):收集整个Java堆和方法区的垃圾收集
虽然我们对各个收集器进⾏⽐较,但并⾮要挑选出⼀个最好的收集器。
因为知道现在为⽌还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,我们能做的就是根据具体应⽤场景选择适合⾃⼰的垃圾收集器。
试想⼀下:如果有⼀种四海之内、任何场景下都适⽤的完美收集器存在,那么我们的HotSpot虚拟机就不会实现那么多不同的垃圾收集器了。
各种垃圾回收器的比较
垃圾回收器的搭配
下面这种图是各个垃圾收集器的搭配,上面的是新生代的收集器,下面是老年代的收集器
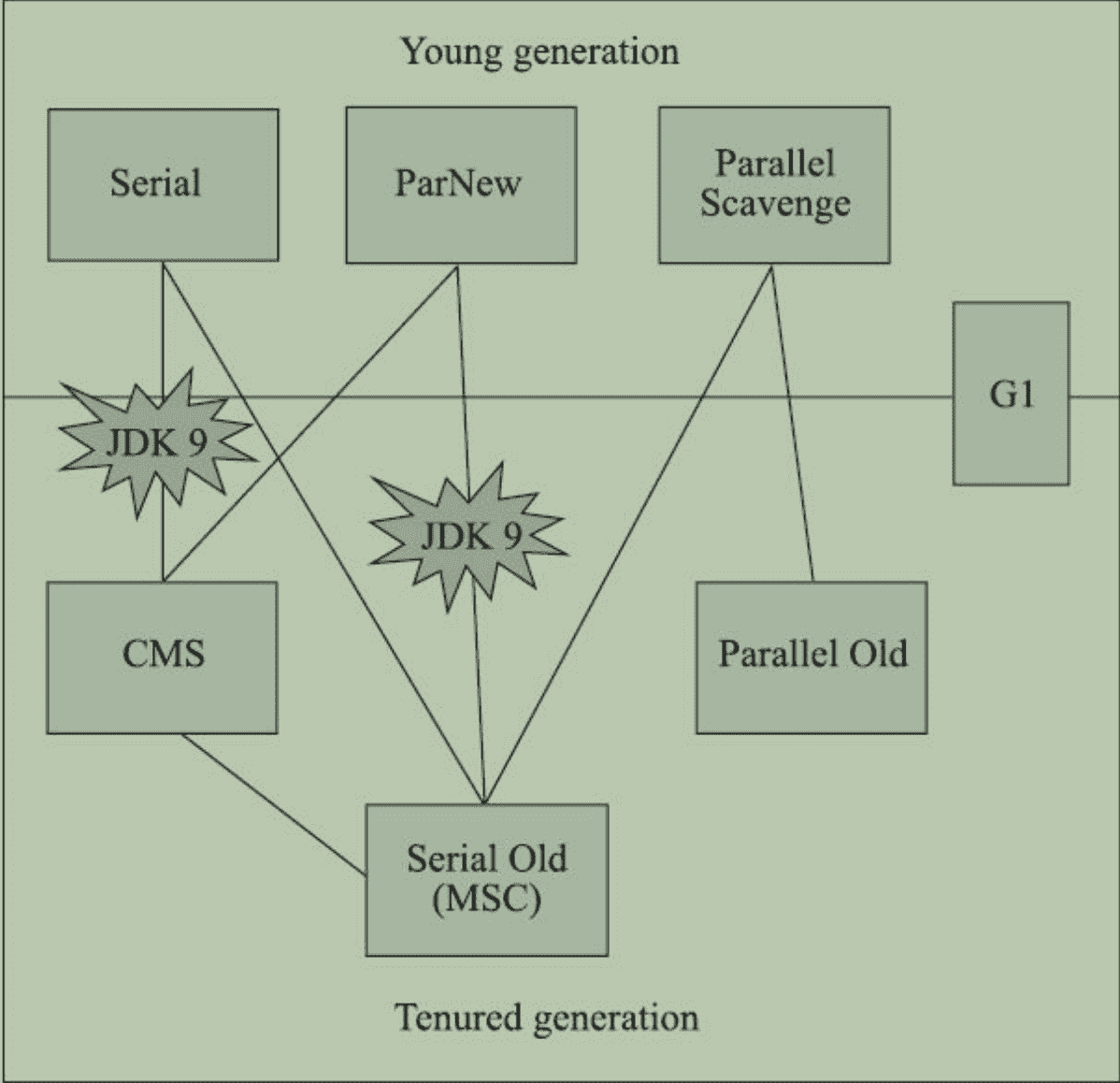
一般会有这么几种搭配方案
- Serial收集器 + Serial Old收集器:单线程,适合单核
- ParNew收集器 + CMS收集器:追求低停顿
- Parallel Scavenge收集 + Parallel Old 收集:追求高吞吐
- G1 收集器:新一代,可指定停顿时间
STW
STW既stop the world,暂停用户线程。为什么需要这样呢?
因为当用户线程和回收线程并发期间,用户线程如果不暂停,新加入的垃圾可能会错过这次回收,所以我们在标记垃圾的时候,需要先暂停用户线程。
标记完后,如果只是把垃圾清除,那么这个过程就不需要停顿用户线程。如果还需要整理,那么这个过程还需要停顿。
所以追求速度的CMS处理器,采用的是标记-清除算法,当然也考虑到后期碎片过多,无法分配内存的问题,所以还设置了一个参数控制几次清除后整理。
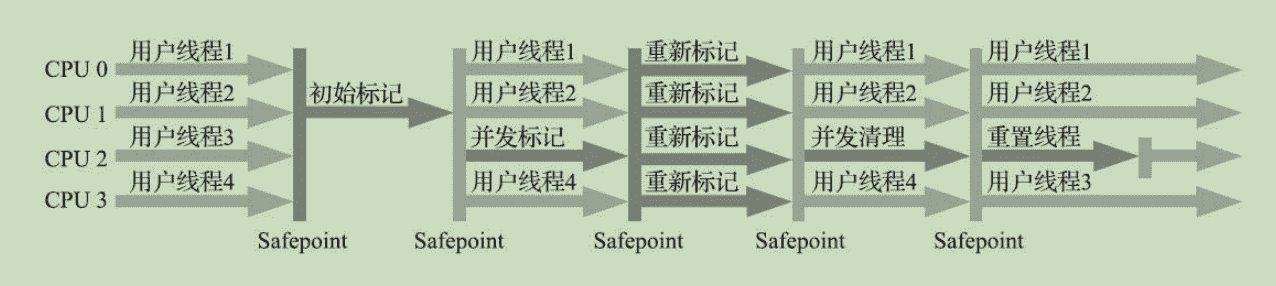
CMS收集器的收集过程
(1)初始标记(CMS initial mark):标记gc roots。会STW
(2)并发标记(CMS concurrent mark) 往下遍历。不STW
(3)重新标记(CMS remark) 修正并发标记。会STW
(4)并发清除(CMS concurrent sweep)标记清除。不STW
- 对象优先在Eden分配
- 大对象直接进入老年代 -XX:PretenureSizeThreshold
- 长期存活的对象直接进入老年代 -XX:MaxTenuringThreshold
- 空间分配担保: 前面说过,新生代使用复制收集算法,但为了内存利用率, 只使用其中一个Survivor空间来作为轮换备份,如果出现大量对象在Minor GC后仍然存活的情况 ——最极端的情况就是内存回收后新生代中所有对象都存活,需要老年代进行分配担保,把Survivor无法容纳的对象直接送入老年代
通过调整内存设置来减少gc的次数
- -Xmx 最大堆大小
- -Xms 初始堆大小,一般=Xmx,防止扩容带来的损耗
- -Xmn 新生代大小
- -XX:SurvivorRatio 默认=8,既新生代中Eden与两个s区的比例是 8:1:1
- -Xss 最大栈大小
- -XX:MaxMetaspaceSiz 最大元空间大小