其实大部分中间件都逃不过这两种模式
这种模式的特点是有一Master多slave,一般采用读写分离的方式,只从master中写,然后同步给slave,半数以上成功才算同步成功。读是通过负载均衡从所有的slave中读。
一般能保证CP,既强一致性
缺点:master挂了正在选主,或者半数机器挂了,就会无法获取数据
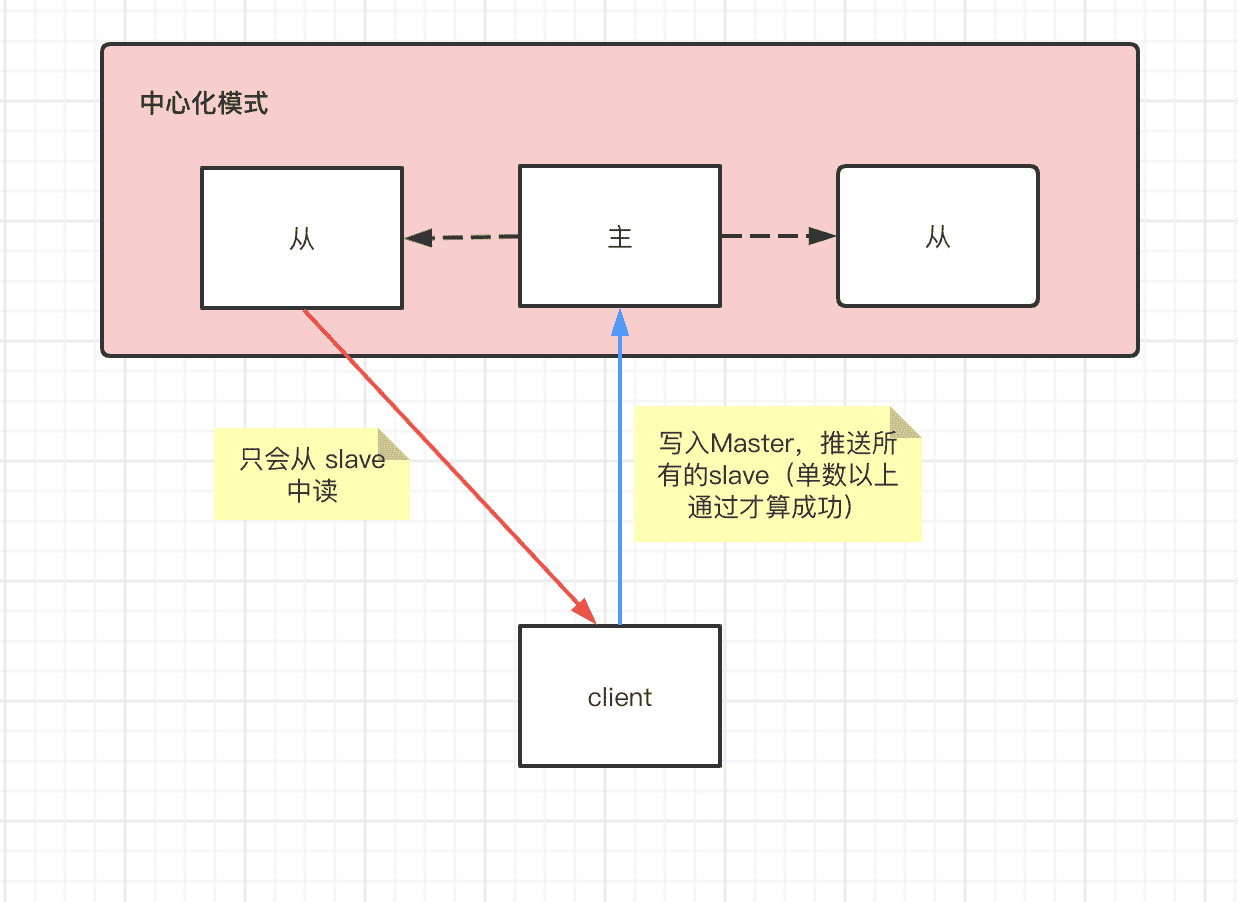
常见场景:redis主从、哨兵,mysql,zk
既所有机子都是通过负载均衡来承担读写一台机子写入后同步给其他机子。
节点之间互相平等,部分挂掉也不会影响,即使只有一台存活
缺点:可能会出现数据的不一致
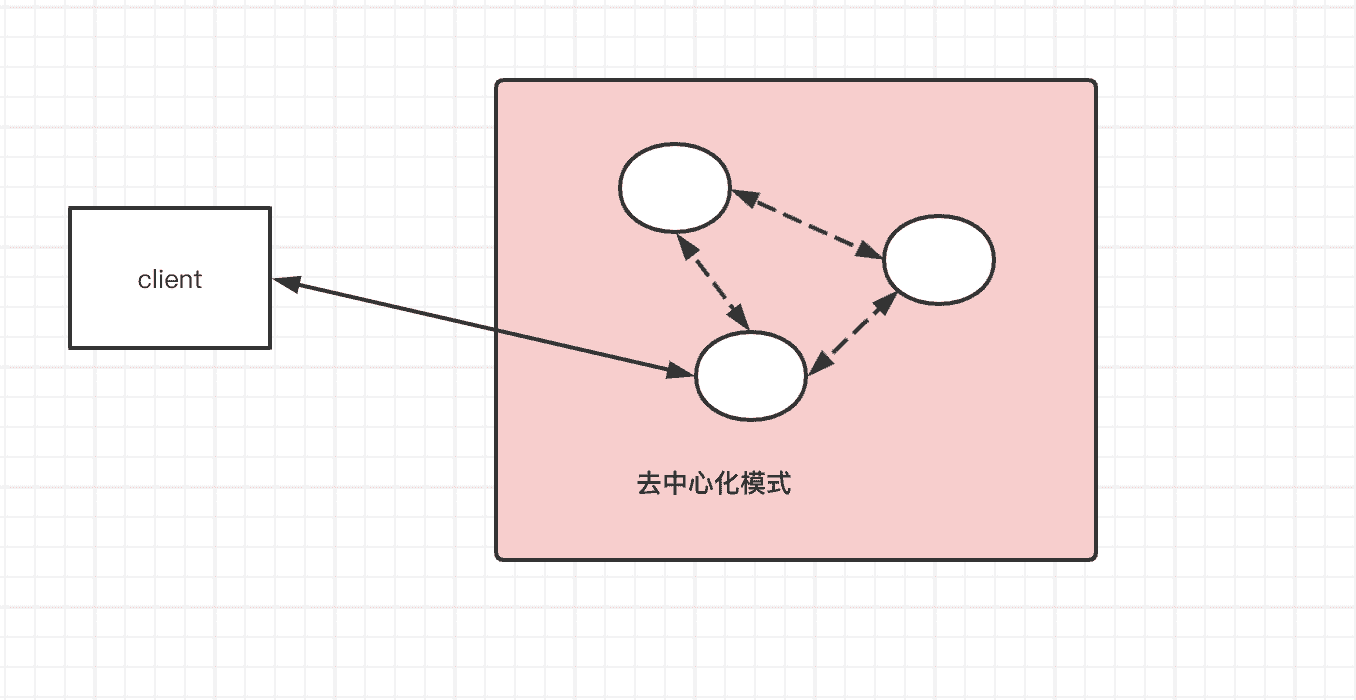
一般能保证AP,高可用性
常见场景:redis cluster,eureka
CP和AP的选择
对于大多数分布式环境,尤其是涉及数据存储的场景,数据一致性应该是要首先被保证的。
如果是服务发现场景的话,针对同一个服务,即使注册中心的不同节点保存的服务提供者不一致,也不会造成灾难性的后果,对于消费者而言,能够消费才是最重要的。
所以,对于服务发现而言,可用性比一致性更重要
负载均衡算法
- 随机
- 轮训
- hash
- 比重
这里讲一下一致性hash算法
我需要通过hash值算出在哪台机器,常用的方法就hash值对服务器的数量取模 hashCode % servers.size()这种算法的好处就是,会有粘性,我下次进来还是会进同一台。
但是这样会有一个问题,比如服务器增加了一台或者减少了一台,那么所有取值都会变化。
于是我们改成对2^32取模,这些节点会落在一个圆上。当我们请求过来时, 根据 hashCode % 2^32取值,然后顺时针找到最近的节点,就是我们要访问的机子。
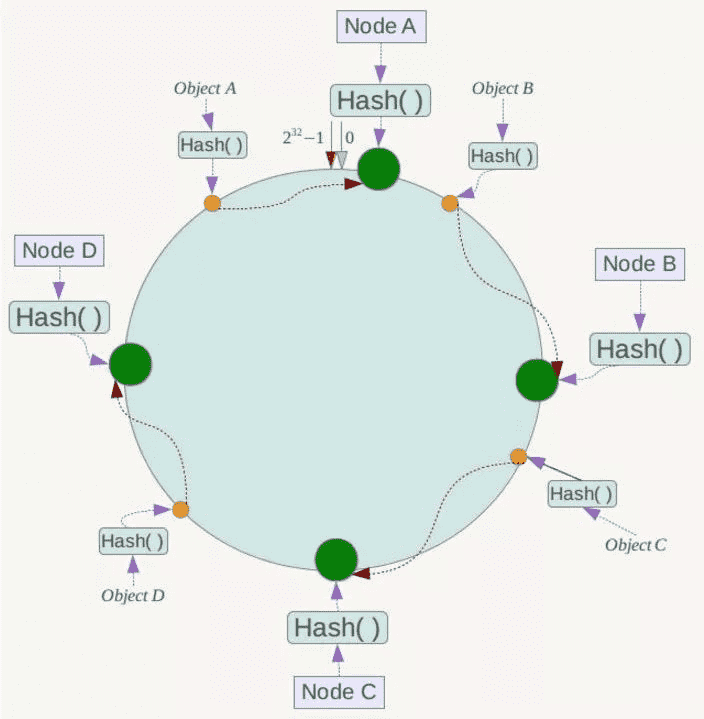
如果服务器的数量很少,那么这些节点在这个圆上可能不是那么均匀,大量数据可能会集中在一个节点上,这时候引入了虚拟节点的概念,多了几个虚拟节点后就不会显得那么不均匀了
具体可见 https://zhuanlan.zhihu.com/p/34985026