最近博主搞了一个博客网站,但是遇到一个头疼的事情,就是要把以前写在csdn 上的博客批量导出成markdown文件,但是csdn上只支持单个导出,而且我的博客网站是用jekyll搭的,还需要在每个md里面另外加一些配置信息,要是得一个个导出一个个改那可得累死我喽。于是我网站搜了一些资料,发现网上有一些用python写的爬虫,我想为什么我不自己用java写一个爬虫实现这个功能呢?
- 打开博客列表
- 获取每篇文章的id
- 打开每篇文章的详情
- 转成md文件
具体如图所示
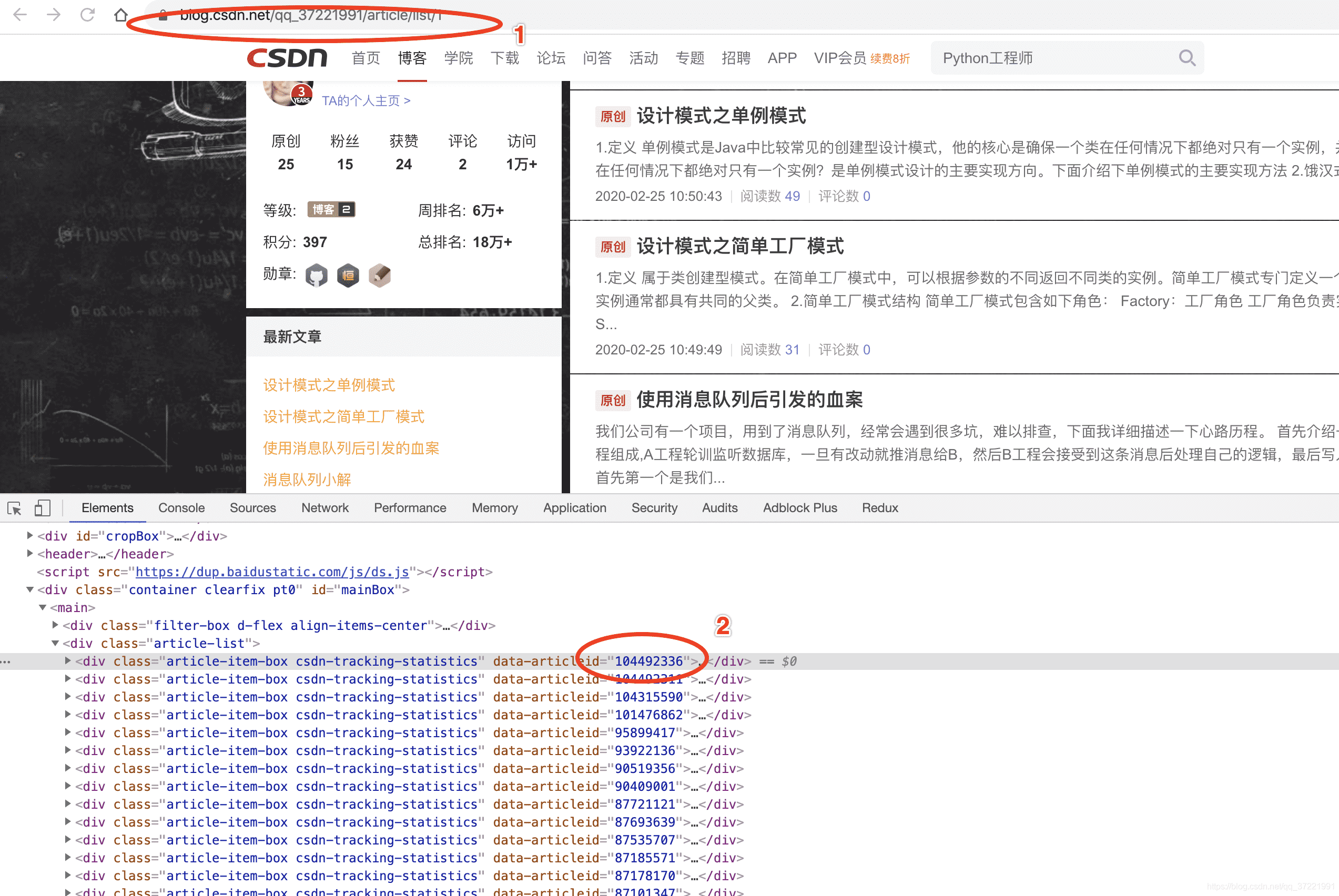
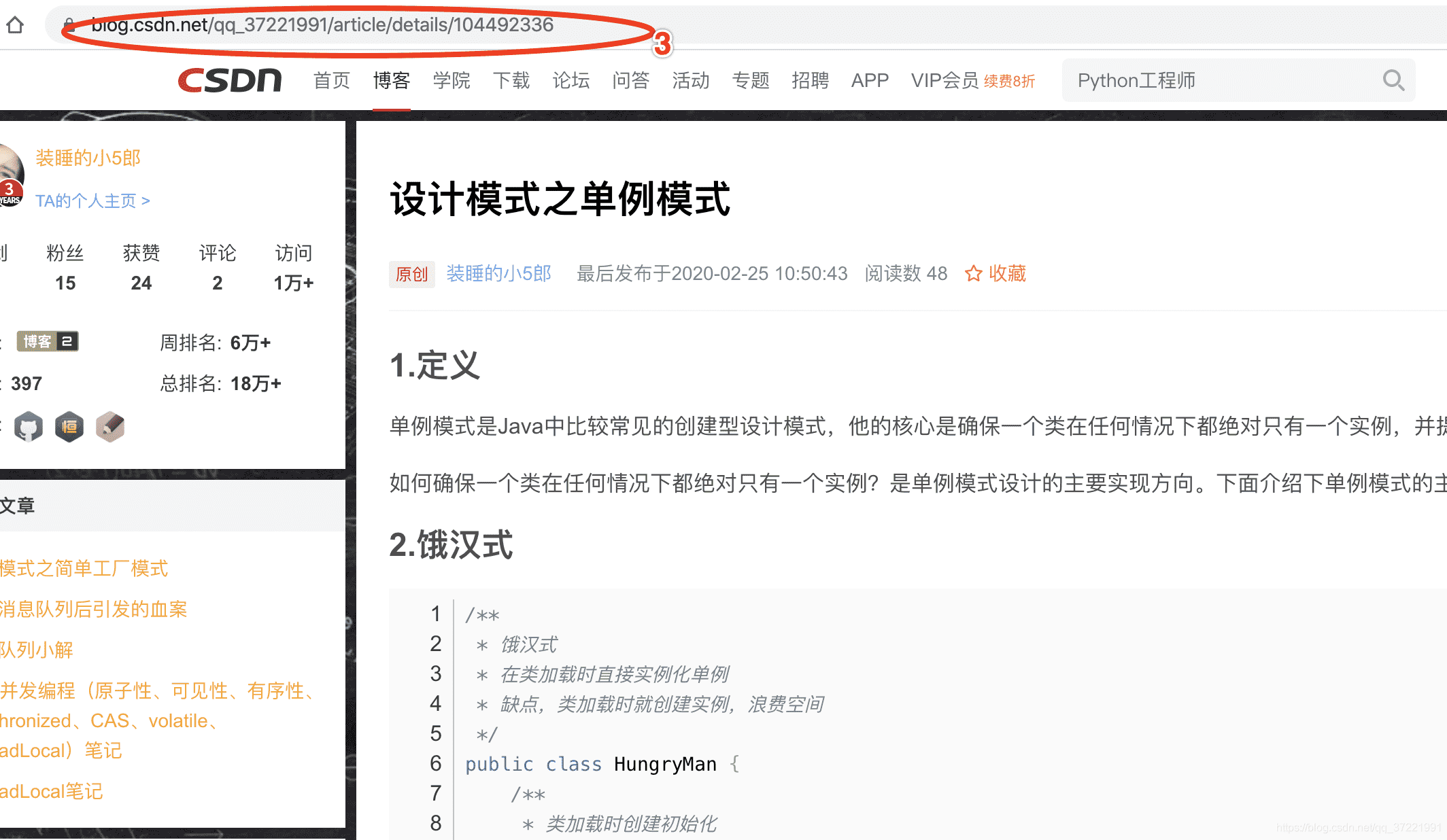
我是用Jsoup来爬取网页的,这个库用起来十分方便,里面的api基本跟用js获取html元素差不多,易上手。具体介绍见这篇文章
使用时只要改下main方法的userName,改成自己的就行了,md文件在_post下 使用了jsoup来爬取,使用起来分很方便。 具体逻辑如下
/**
* 爬csdn博客工具
* create by zhangtao
*/
public class climbUtil {
public static void main(String[] args) {
climb("qq_37221991");
}
private static void climb(String userName) {
System.out.println("》》》》》》》爬虫开始《《《《《《《");
// 把下面这个base_url换成你csdn的地址
String baseUrl = "https://blog.csdn.net/" + userName + "/";
String secondUrl = baseUrl + "article/list/";
// 创建文件夹
File file = new File("./_posts/");
if (!file.exists()) {
file.mkdir();
}
for (int i = 1; ; i++) {
// 从第一页开始爬取
String startUrl = secondUrl + i;
Document doc = null;
try {
doc = Jsoup.connect(startUrl).get();
} catch (IOException e) {
System.out.println("jsoup获取url失败" + e.getMessage());
}
Element element = doc.body();
//找到div class='article-list'
element = element.select("div.article-list").first();
if (element == null) {
break;
}
Elements elements = element.children();
for (Element e : elements) {
// 拿到文章id
String articleId = e.attr("data-articleid");
System.out.println(articleId);
// 爬取单篇文章
climbDetailById(baseUrl, articleId);
}
}
System.out.println("》》》》》》》爬虫结束《《《《《《《");
}
private static void climbDetailById(String baseUrl, String articleId) {
String startUrl = baseUrl + "article/details/" + articleId;
Document doc = null;
try {
doc = Jsoup.connect(startUrl).get();
} catch (IOException e) {
System.out.println("jsoup获取url失败" + e.getMessage());
}
Element element = doc.body();
Element htmlElement = element.select("div#content_views").first();
Element titleElement = element.selectFirst(".title-article");
String fileName = titleElement.text();
System.out.println(fileName);
// 设置jekyll格式博客title
String jekyllTitle = "title: " + fileName + "\n";
// 设置jekyll格式博客categories
Elements elements = element.select("div.tags-box");
String jekyllCategories = "";
if (elements.size() > 1) {
jekyllCategories = "categories:\n";
jekyllCategories = getTagsBoxValue(elements, 1, jekyllCategories);
}
// 设置jekyll格式博客tags
String jekyllTags = "tags:\n";
jekyllTags = getTagsBoxValue(elements, 0, jekyllTags);
// 获取时间
Element timeElement = element.selectFirst("span.time");
String time = timeElement.text().substring(5);
System.out.println(time);
// 设置jekyll格式博客date
String jekyllDate = "date: " + time + "\n";
String md = Html2Md.getMarkDownText(htmlElement);
// String md = HtmlToMd.getTextContent(htmlElement); 转出来的效果不满意,弃用
System.out.println(md);
String jekylltr = "---\n" + "layout: post\n" + jekyllTitle + jekyllDate
+ "author: 'zhangtao'\nheader-img: 'img/post-bg-2015.jpg'\ncatalog: false\n"
+ jekyllCategories + jekyllTags + "\n---\n";
String date = time.split(" ")[0];
String mdFileName = "./_posts/" + date + '-' + fileName + ".markdown";
md = jekylltr + md;
FileWriter writer;
try {
writer = new FileWriter(mdFileName);
writer.write(md);
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
private static String getTagsBoxValue(Elements elements, int index, String jekyllCategories) {
Elements categories = elements.get(index).select("a.tag-link");
for (Element e : categories) {
String temp = e.text().replace("\t", "").replace("\n", "").replace("\r", "");
jekyllCategories += "-" + temp + "\n";
}
return jekyllCategories;
}
}
末尾附送源码地址 https://github.com/zntzhang/climbCSDNblogsUtils